HyperDeduplicator™ for High-Speed Multi Biometric Deduplication
Superscalar, one-to- many biometric deduplication server for large-scale biometric deduplication of fingerprint, finger vein, facial and iris biometric data.
HyperDeduplicator™
HyperDeduplicator™ is a fast biometric deduplication system capable of deduplicating millions of biometric templates within a very short period of time. This high-performance deduplication system can be used with any large-scale biometric system in the back-end to deduplicate and check data for inconsistencies. Unlike other systems, HyperDeduplicator™ does not rely on slow and computing resource intensive one-to-many (1: N) biometric matching operations to Deduplicate large databases of fingerprints.
Why Do You Need to Deduplicate?
For a large-scale biometric project like a biometric voting, imagine that there are 10 million people registered to vote. Usually, all data is collected in individual laptops and then merged into a central database. Before the voter ID is issued, the authorized agency wants to make sure that one person did not register multiple times. This can be done using Biometric Deduplication software such as HyperDeduplicator™. Moreover, to merge any decentralized biometric data into a central system requires identifying all duplicate records to unify transaction data under unique person identities. Therefore, any decentralized biometric projects in areas such as banking, micro-credit lending, membership management, access control, and hospitals or rural clinics can significantly benefit from a biometric deduplication system.
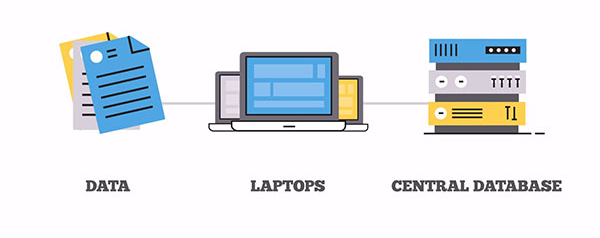
How Is It Done?
Typically, biometric providers load the entire biometric database into computer servers and then search each record against the entire database – they need to perform as many searches as the actual number of records in the database. In short, if the biometric database consists of 10 million records, performing deduplication with traditional biometric software requires performing 10 million one-to-many searches! If each biometric search takes one second, the deduplication would take 10 million seconds or approximately 120 days to complete! To compensate for this, traditional deduplication software companies will deploy multiple servers to increase the processing power and shorten the completion time.
Fortunately, M2SYS invented a deduplication specific algorithm to address this issue. We load the entire biometric database (e.g. 10 million records) on one server and our software runs a filtering step like an industrial separation process – in few hours, all duplicates come out like MAGIC. Our HyperDeduplicator™ solution is the only software that performs Biometric deduplication without any one-to-many (1:N) biometric searches.